

_-The-Breakthrough-Antipsychotic-That-Could-Change-Everything.webp?t=1729528747 "KarXT (Cobenfy)_ The Breakthrough Antipsychotic That Could Change Everything.jpg")
Investigating Bias in Research
Unbiased medical research is essential to the process of informed clinical decision-making. Unfortunately, some degree of research bias is unavoidable, so the best approach to conducting a study is to attempt to minimize bias, wherever possible.
Bias in research can be defined as any “condition that produce(s) results which depart from the true values (in a study) in a consistent direction” (Riegelman RK, Studying a Study and Testing a Test, 4th ed: Lippincott Williams & Wilkins, Philadelphia;2000). Bias is also referred to as “systematic error.”
It’s important to understand what bias is not. Bias is not fraud, as it does not involve intentional prejudice. Bias is also not random error, which creates deviation in results strictly by chance, and can be mitigated with a large enough study sample.
Put simply, bias has to do with the unintentional skewing of results due to human failings such as poor trial design or unconscious wishes for desirable outcomes.
Bias can occur anywhere in the process from initial concept to publication. For convenience, we will examine four stages in the research process—study design, study implementation, data analysis, and post study/publication—and the biases inherent in these stages (although there is a certain amount of overlap).
Biases in Study Design
To avoid bias, any study needs to be fully and clearly conceptualized from the outset.
Conditions and subjects need to be well defined to avoid definition bias. Examples of definition bias are ambiguity about what constitutes severe versus moderate anxiety, or what score on a symptom rating scale qualifies a subject for a trial.
Similarly, outcome measures should be as objective as possible. This can be tricky. Rating scales seem objective, but when used properly they may require extensive subjective judgment on the part of the rater.
The Hamilton Rating Scale for Depression (HAM-D), for instance, is often used to rate severity of depression. In the 1960 article introducing the scale, its creator, Max Hamilton, wrote that it should be “used for quantifying the results of an interview, and its value depends entirely on the skill of the interviewer in eliciting the necessary information” (Hamilton M, J Neurol Neurosurg Psychiat 1960;23:56–62).
Relevant outcome measures should be defined before the study is conducted. However, it’s sometimes impossible for the reader to determine what these are. For instance, a study’s primary outcome (eg, depression severity) may be negative, while a secondary outcome (eg, anxiety symptoms) gives statistically significant results.
Reporting only the secondary outcome may be an attempt to salvage a serendipitous—and sometimes useful—conclusion from what would otherwise be a negative and costly study, but it wasn’t what the researchers intended to study.
Selection bias occurs when the study and control groups differ in ways that might influence the outcome of the study. This can be controlled for by matching study and control groups to ensure that a particular variable, such as average age or health status, is the same in both groups. Unfortunately, the matched variable can no longer be studied as a determinant of outcome.
In pairing, a type of matching, individual subjects are paired with individual controls who have exactly the same characteristics, apart from the ones the study is assessing.
Alternatively, some studies use a crossover study design, in which the subject is used as his or her own control. For example, the same patient can be assessed on no medication, and later, on the study medication. This may be a problem because the subject may know when he or she is taking a medication (versus placebo). There may also be carry-over effects from one phase to the next. This can be avoided through the use of a washout period.
Self-selection bias can occur whenever volunteers are recruited for a study, since volunteers are often not representative of the general population. A related bias, frequently found in medical research, is known as Berkson’s bias, in which subjects are selected from an “enriched” population. For example, an epidemiological study of patients recruited from a specialty mood disorders clinic may identify characteristics that are not widespread among the more general population of psychiatric outpatients.
Biases in Study Implementation
Interviewer bias refers to a systematic skewing of the way data is elicited, recorded, or interpreted (Pannucci CJ & Wilkins EG, Plast Reconstr Surg 2010;126(2):619–625). For example, an interviewer might ask, “Have you ever been diagnosed with social phobia?” as opposed to questions like “Do you ever get anxious in crowds?” The best remedy for interviewer bias is to use a standardized measurement tool and to ensure the interviewer is blind to the subject’s history.
Bias can also be introduced by the subjects themselves. Recall bias occurs when the subjects in one arm of a study are more likely to remember past events than the subjects in another arm. This type of bias commonly occurs in case-control studies of traumatic outcomes. For example, women who give birth to babies with congenital malformations may be more likely to remember taking psychotropic drugs during pregnancy than women with normal babies.
Similarly, reporting bias is common when sensitive information is being elicited, such as a patient’s sexual history. A good study design should try to reduce recall and reporting biases, for example by assessing specific symptoms, side effects, or historical details, rather than asking open-ended questions.
Performance bias, in which there are selective differences between the care that is given to different groups, is a particular problem in studies of psychotherapy. Some therapies, such as CBT, are fairly easy to standardize (a process called manualization). But with other psychotherapies, it’s harder to control for variations in treatment, and differences in therapists’ styles and levels of experience can heavily influence outcomes.
Biases in Data Analysis
Confounding factors can be a significant source of bias in data analysis. For example, a study might conclude that schizophrenia is a risk factor for lung cancer. This conclusion misses the role that smoking plays in both illnesses. To correct for this, an adjustment must be made that separately analyzes subjects who smoke and those who do not.
A major issue in psychiatric clinical trials is how to deal with subjects who drop out of the study, also called attrition bias. There are two ways researchers can deal with the lost data.
In a per-protocol analysis, drop-outs from the active arm of a trial are treated as though they had never been given the active intervention. In other words, only the subjects who finished per-protocol are included. Thus, a per-protocol analysis only looks at those subjects in the active arm of a trial who found an intervention tolerable and potentially helpful, not those who dropped out for any reason, so it usually overestimates the effect of the intervention.
In contrast, an intention-to-treat analysis is designed to measure everybody who enters the trial (ie, everyone who was “intended to be treated”). When subjects drop out before the end of the trial, their final results may be estimated based on measurements already taken.
Alternatively (and more commonly), researchers can take the most recent assessment and assume that it will also be the subject’s final measurement. This is called last-observation carried forward (LOCF). LOCF is much more conservative, making it the more acceptable approach, even though it is, strictly speaking, an inaccurate representation of the data.
Biases in Post Study/Publication
Publication bias is the tendency not to publish small trials that don’t demonstrate statistical significance. It’s understandable that this happens—if a study’s researchers have nothing to show for their efforts, they may choose not to devote the time and effort to writing up their results.
For example, researchers found in 2008 that out of 74 antidepressant trials submitted to the FDA, 38 were positive and 36 were negative. Interestingly, nearly all (37) of the positive trials were published in peer-reviewed journals, while only six of the negative trials were published, sometimes spun to sound positive (Turner EH et al, NEJM 2008;358:252–260). The average reader wouldn’t know this, and may be practicing evidence-based medicine without all the evidence (see also “Overview of the FDA Drug Approval Process” in this issue).
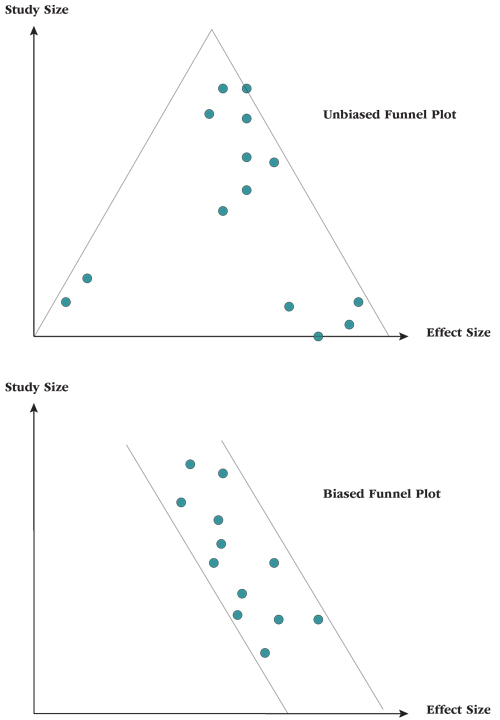
When multiple published studies are compared, as in a meta-analysis, publication bias is easy to detect, by using a funnel diagram. The X-axis is a measure of treatment effect (eg, effect size, very low to very high), while the Y-axis is a measure of the size of the trials.
When there is no publication bias, the graph resembles an upside down funnel: smaller studies are more subject to chance, so the reported effect of treatment can be widely variable, whereas larger studies tend to report comparable effect sizes near the true value of the effect. When publication bias does exist, the smaller trials are missing, because they haven’t been published, and the results are skewed.
Sometimes researchers report only results that are significant, ignoring those that were insignificant or unfavorable, something known as outcome reporting bias. Recent grass-roots initiatives like AllTrials (www.alltrials.net) demand that the protocols and Clinical Study Reports (CSRs) for all drug trials be made available to independent researchers, to determine whether authors cherry-pick their data or simply refuse to publicize trials that are negative—often called the “file-drawer effect” (See TCPR, Nov. 2013, for more on AllTrials.)
Another useful resource is trialsjournal.com, an open-access online journal that aims to publish results of studies regardless of outcome or significance of findings.
Related to publication bias is grey literature bias, which occurs when non-peer-reviewed sources like dissertations and posters give different results from those found in the published literature. Poster presentations at conferences can be good ways to keep up with new research, but their results are not peer-reviewed and must be considered preliminary.
TCPR’s Verdict: Most readers of medical literature are not also professional researchers, and may not be familiar with the various biases in clinical research, both intentional and unintentional. Hopefully, readers can become more aware of the potential pitfalls in interpreting the literature to avoid drawing their own erroneous conclusions.
General PsychiatryBias in research can be defined as any “condition that produce(s) results which depart from the true values (in a study) in a consistent direction” (Riegelman RK, Studying a Study and Testing a Test, 4th ed: Lippincott Williams & Wilkins, Philadelphia;2000). Bias is also referred to as “systematic error.”
It’s important to understand what bias is not. Bias is not fraud, as it does not involve intentional prejudice. Bias is also not random error, which creates deviation in results strictly by chance, and can be mitigated with a large enough study sample.
Put simply, bias has to do with the unintentional skewing of results due to human failings such as poor trial design or unconscious wishes for desirable outcomes.
Bias can occur anywhere in the process from initial concept to publication. For convenience, we will examine four stages in the research process—study design, study implementation, data analysis, and post study/publication—and the biases inherent in these stages (although there is a certain amount of overlap).
Biases in Study Design
To avoid bias, any study needs to be fully and clearly conceptualized from the outset.
Conditions and subjects need to be well defined to avoid definition bias. Examples of definition bias are ambiguity about what constitutes severe versus moderate anxiety, or what score on a symptom rating scale qualifies a subject for a trial.
Similarly, outcome measures should be as objective as possible. This can be tricky. Rating scales seem objective, but when used properly they may require extensive subjective judgment on the part of the rater.
The Hamilton Rating Scale for Depression (HAM-D), for instance, is often used to rate severity of depression. In the 1960 article introducing the scale, its creator, Max Hamilton, wrote that it should be “used for quantifying the results of an interview, and its value depends entirely on the skill of the interviewer in eliciting the necessary information” (Hamilton M, J Neurol Neurosurg Psychiat 1960;23:56–62).
Relevant outcome measures should be defined before the study is conducted. However, it’s sometimes impossible for the reader to determine what these are. For instance, a study’s primary outcome (eg, depression severity) may be negative, while a secondary outcome (eg, anxiety symptoms) gives statistically significant results.
Reporting only the secondary outcome may be an attempt to salvage a serendipitous—and sometimes useful—conclusion from what would otherwise be a negative and costly study, but it wasn’t what the researchers intended to study.
Selection bias occurs when the study and control groups differ in ways that might influence the outcome of the study. This can be controlled for by matching study and control groups to ensure that a particular variable, such as average age or health status, is the same in both groups. Unfortunately, the matched variable can no longer be studied as a determinant of outcome.
In pairing, a type of matching, individual subjects are paired with individual controls who have exactly the same characteristics, apart from the ones the study is assessing.
Alternatively, some studies use a crossover study design, in which the subject is used as his or her own control. For example, the same patient can be assessed on no medication, and later, on the study medication. This may be a problem because the subject may know when he or she is taking a medication (versus placebo). There may also be carry-over effects from one phase to the next. This can be avoided through the use of a washout period.
Self-selection bias can occur whenever volunteers are recruited for a study, since volunteers are often not representative of the general population. A related bias, frequently found in medical research, is known as Berkson’s bias, in which subjects are selected from an “enriched” population. For example, an epidemiological study of patients recruited from a specialty mood disorders clinic may identify characteristics that are not widespread among the more general population of psychiatric outpatients.
Biases in Study Implementation
Interviewer bias refers to a systematic skewing of the way data is elicited, recorded, or interpreted (Pannucci CJ & Wilkins EG, Plast Reconstr Surg 2010;126(2):619–625). For example, an interviewer might ask, “Have you ever been diagnosed with social phobia?” as opposed to questions like “Do you ever get anxious in crowds?” The best remedy for interviewer bias is to use a standardized measurement tool and to ensure the interviewer is blind to the subject’s history.
Bias can also be introduced by the subjects themselves. Recall bias occurs when the subjects in one arm of a study are more likely to remember past events than the subjects in another arm. This type of bias commonly occurs in case-control studies of traumatic outcomes. For example, women who give birth to babies with congenital malformations may be more likely to remember taking psychotropic drugs during pregnancy than women with normal babies.
Similarly, reporting bias is common when sensitive information is being elicited, such as a patient’s sexual history. A good study design should try to reduce recall and reporting biases, for example by assessing specific symptoms, side effects, or historical details, rather than asking open-ended questions.
Performance bias, in which there are selective differences between the care that is given to different groups, is a particular problem in studies of psychotherapy. Some therapies, such as CBT, are fairly easy to standardize (a process called manualization). But with other psychotherapies, it’s harder to control for variations in treatment, and differences in therapists’ styles and levels of experience can heavily influence outcomes.
Biases in Data Analysis
Confounding factors can be a significant source of bias in data analysis. For example, a study might conclude that schizophrenia is a risk factor for lung cancer. This conclusion misses the role that smoking plays in both illnesses. To correct for this, an adjustment must be made that separately analyzes subjects who smoke and those who do not.
A major issue in psychiatric clinical trials is how to deal with subjects who drop out of the study, also called attrition bias. There are two ways researchers can deal with the lost data.
In a per-protocol analysis, drop-outs from the active arm of a trial are treated as though they had never been given the active intervention. In other words, only the subjects who finished per-protocol are included. Thus, a per-protocol analysis only looks at those subjects in the active arm of a trial who found an intervention tolerable and potentially helpful, not those who dropped out for any reason, so it usually overestimates the effect of the intervention.
In contrast, an intention-to-treat analysis is designed to measure everybody who enters the trial (ie, everyone who was “intended to be treated”). When subjects drop out before the end of the trial, their final results may be estimated based on measurements already taken.
Alternatively (and more commonly), researchers can take the most recent assessment and assume that it will also be the subject’s final measurement. This is called last-observation carried forward (LOCF). LOCF is much more conservative, making it the more acceptable approach, even though it is, strictly speaking, an inaccurate representation of the data.
Biases in Post Study/Publication
Publication bias is the tendency not to publish small trials that don’t demonstrate statistical significance. It’s understandable that this happens—if a study’s researchers have nothing to show for their efforts, they may choose not to devote the time and effort to writing up their results.
For example, researchers found in 2008 that out of 74 antidepressant trials submitted to the FDA, 38 were positive and 36 were negative. Interestingly, nearly all (37) of the positive trials were published in peer-reviewed journals, while only six of the negative trials were published, sometimes spun to sound positive (Turner EH et al, NEJM 2008;358:252–260). The average reader wouldn’t know this, and may be practicing evidence-based medicine without all the evidence (see also “Overview of the FDA Drug Approval Process” in this issue).
When multiple published studies are compared, as in a meta-analysis, publication bias is easy to detect, by using a funnel diagram. The X-axis is a measure of treatment effect (eg, effect size, very low to very high), while the Y-axis is a measure of the size of the trials.
When there is no publication bias, the graph resembles an upside down funnel: smaller studies are more subject to chance, so the reported effect of treatment can be widely variable, whereas larger studies tend to report comparable effect sizes near the true value of the effect. When publication bias does exist, the smaller trials are missing, because they haven’t been published, and the results are skewed.
Sometimes researchers report only results that are significant, ignoring those that were insignificant or unfavorable, something known as outcome reporting bias. Recent grass-roots initiatives like AllTrials (www.alltrials.net) demand that the protocols and Clinical Study Reports (CSRs) for all drug trials be made available to independent researchers, to determine whether authors cherry-pick their data or simply refuse to publicize trials that are negative—often called the “file-drawer effect” (See TCPR, Nov. 2013, for more on AllTrials.)
Another useful resource is trialsjournal.com, an open-access online journal that aims to publish results of studies regardless of outcome or significance of findings.
Related to publication bias is grey literature bias, which occurs when non-peer-reviewed sources like dissertations and posters give different results from those found in the published literature. Poster presentations at conferences can be good ways to keep up with new research, but their results are not peer-reviewed and must be considered preliminary.
TCPR’s Verdict: Most readers of medical literature are not also professional researchers, and may not be familiar with the various biases in clinical research, both intentional and unintentional. Hopefully, readers can become more aware of the potential pitfalls in interpreting the literature to avoid drawing their own erroneous conclusions.



Recommended


